Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them

Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values

Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight

Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
Now if you want to find “only” ≈93.3% of insights you need only 12.
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Quick win
Yes, this is yet another blog post on number of test participants, but this time it is based on very large samples and statistical wizardry. The total length of remote user research videos recorded by the WhatUsersDo platform in 2014 adds up to a jaw-dropping 2861 hours 03 minutes and 43 seconds. (It would take 120 days to watch them, if you would be watching user videos 24/7 without a break.) The core research for this article is based on 375 videos. After statistically analysing those results, I must say that 5 users is way too low. Most of the time you end up finding about 31% or less of all possible insights. How do I know what is the number of all possible insights? Because we conducted a very large-scale study, and found no unique insights, everything was repeated at least twice. As a result I have created “the big table of problems, research answers and number of tests to solve them“.
Yes, this means that I don’t agree with Jakob Nielsen’s blog post from 2012 claiming For most projects you should stay with the tried-and-true: 5 users per usability test.
Don’t make me think about number of testers
Steve Krug has a famous heading in his even more famous book “Rocket Surgery Made Easy: The Do-It-Yourself Guide to Finding and Fixing Usability problems”. The heading (photographed below) reads: “Three is enough”.
In that chapter he gave user experience experts an easy way to avoid user exposure. He basically recommends 3 users in each round of testing. He claims that the first three users are very likely to encounter many of the most significant problems related to the tasks you’re testing
.
{kind=link}
This even more famous book, “Don’t Make Me Think! A Common Sense Approach to Web Usability” repeats his claim, and goes even further, and compares one test with 8 users (found 5 problems), and two times 3 users found 9 (problems total). While the illustration looks great, it is unfortunately not based on reality, as I will shortly demonstrate.
I think in the majority UXers are interested in “how many tests are enough”, so I will tell you the numbers first and then I will explain how I came up with them.
{kind=link}
How many test are enough?
The bad news is to find all (≈99.99966%) possible UX issues for a fairly complex webshop (to be honest: the exact one we tested) you need 250 tests.
The good news is in the real world you can get away with a lot less. I have calculated that just 46 tests will give you ≈93.3% of insights.
How many users does it take to change a light bulb?
If the the test is less complex (I will speak about complexity later), then the number of tests will be a lot lower.
The test design is as follows: Imagine that you need to buy a new light bulb, and you start at the home page of a site that sells light bulbs and go on to buy one. If you want to find all issues, you need 63 users even on this simple looking test.
{kind=link}
Now if you want to find “only” ≈93.3% of insights you need only 12.
{kind=link}
Diminishing returns
Now returning to the original (more complex) scenario, you can see what I mean by diminishing returns on user tests. 46 tests gives you roughly 93%, but you need 76 for an increase to roughly 99%. So with 30 additional tests you gain about 6 percentage points. Consult the graph below, and decide what’s the best for you.
I recommend 3 sigma (3σ ≈93.3%) as optimum if you want to improve your website, and 1 sigma (1σ ≈31%) as minimum if you want to build a business case (maybe to prove to senior management that a few things are wrong with the site and you need to run some further tests).
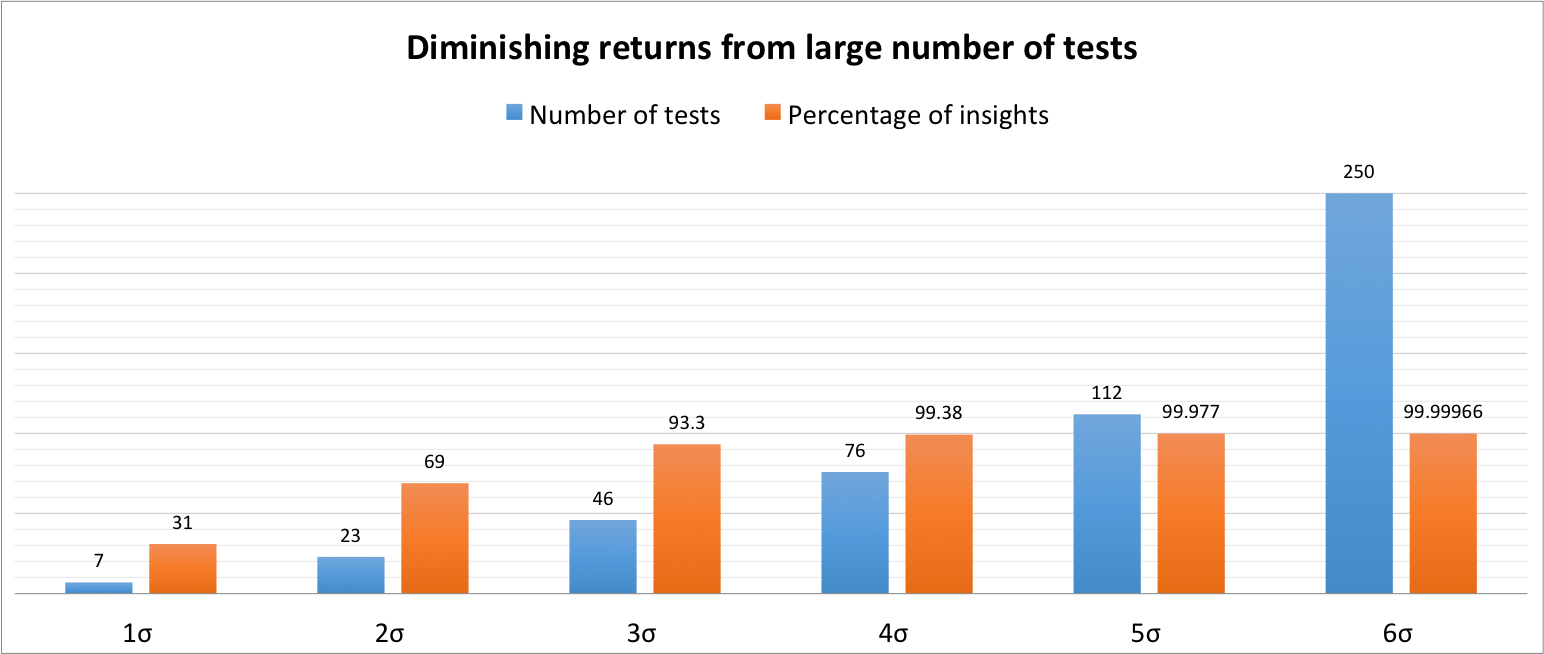{kind=link}
The big table of problems, research answers and number of tests to solve them
Multiplatform multiplier table
One of the most deadly sins of UX design is neglecting mobile. But to test on multiple devices you need to run an increased number of tests, to find all device specific insights. Based on further research we have found out, that to find an equal percentage of issues on two different device types you don’t need to double the number of tests, instead multiply the number by 1.56 and round-up to the nearest integer. If you want to test with even more device types the multipliers are even better, see the table below. Note that this is only true if you run the same test design on the same site/app that is ported/responsive, but will not be true if you create a different site for mobile. Generically this is only true for different types of responsive webdesigns or solutions that are based on the same source (for example a game created with Unity tested on iOS and Android smartphones). Fortunately that was the case for most projects we researched in 2014.
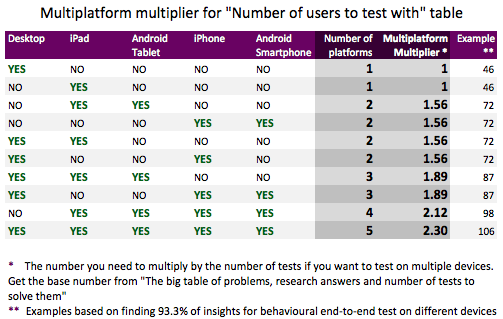{kind=link}
How do we know 3 is not enough?
If you keep reading this, it means user testing and/or statistics is close to your heart. (So please comment on this article, because I’m really interested in what fellow UX testing enthusiasts think about this.) Now let’s get geeky! We ran the same remote user test design on a very large sample size (n=375). That’s 375 different users doing the same tasks on the same website. We run it in 3 equal batches (n=125), named a, b and c. After looking at all issues from all 3 batches what we realised is that each issue was repeated. In fact, tests in the 3rd batch (there where 3 batches of 125 each) yielded issues which we already encountered in the 1st or 2nd match.
The screenshot below shows a small part of an Excel spread sheet tab, one which contains only batches a and b (we put c to a separate tab for clarity and to easily check if there is an issue not encountered in batch a and b).
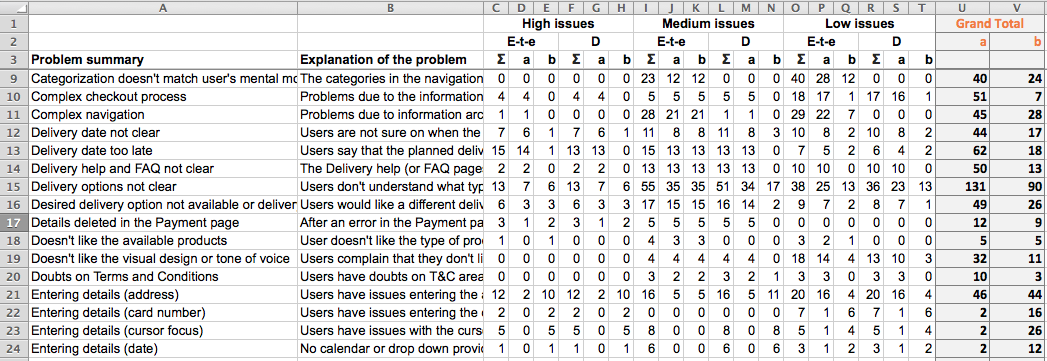{kind=link}
We studied all 3 batches individually and what we found is stunning
Batch ‘a’ had 1 unique issue, and ‘b’ also had an issue that was not repeated, accidentally ‘c’ had no unique issue at all. How is this possible, if there was no unique issue in the whole experiment? Actually the single unique issue in ‘a’ was the same issue as the one in ‘b’.
One issue is a very small percentage of all issues found. In the 3 batches we have found a total of 3823 user experience issues from minor annoyances to conversion blockers. The table below shows the number of issues found in each batch.
I made a leap of faith and called 250 users on this test design for this website “a sample big enough to contain all issues”. I need to emphasise, that if we were to run the same test on the same website with 250 new users we could find a new issue or we could miss one… but it is very-very unlikely.
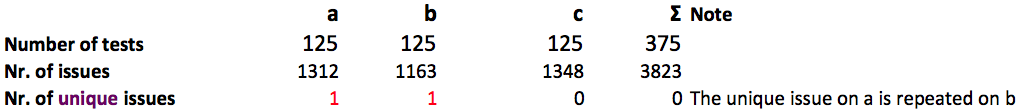{kind=link}
For “a sample big enough to contain all issues” I will use the term six sigma (6σ), borrowed from process improvement statistics. A process where the mean is at least 6σ away from the nearest specification limit is said to be statistically free of defects. This is very fitting, because a missed issue can be defined as a “defect” of the test. A defect resulting from too few tests. But quite contrary to process improvement, we don’t aim for six sigma, because of the diminishing returns shown above, instead I suggest going for 3 sigma for the best RoI (Return on Investment).
Complexity
The numbers found during this research are only valid for that particular test design for that particular website in that particular time (since then the client improved the website, based on our findings).
To apply those numbers to other test designs, I had to introduce complexity values. Each common test type we run got a scalar (a positive rational number) assigned to it, based on empirical observation of how complex each scenario is. Complexity is a multiplier that is based on how many sub-journeys a tester can take during a test and how complex those are. This basically compares the core research to any other user research that we are about to run in the near future.
It is easy to understand why testing on flat visuals or a wireframe needs a lot less users than a natural end-to-end journey of a live webshop run by a major retailer. The empirical approach to complexity might raise a few eyebrows. During the last month (March 2015) we recorded quite a few user-testing videos, the total length is 309 hours 10 minutes 55 seconds just during that particular month. I think based on hundreds of hours worth of user testing videos one can judge scenario complexity fairly accurately, but then again this is based only on empirical observation. If you know of a better solution for this, I would love to hear it. Based on my observations, I ended up with this monster of a table, and I call it:
The Big Table of Sigma Values
Another source of increased number of possible issues and therefore requiring more users is, if you go multiplatform. If you want to test the same site or app across many devices. Originally I wanted to include that into the complexity scalar, but that would have complicated things even further (pun intended). So I decided to create one more multiplier, this time for cross-device tests.
As seen in the “Multiplatform multiplier table” section of this article, the table helps you to calculate the number of tests needed when you want to test on more than one device (and it also fuels your understandable hatred of tables with a lot of funky looking numbers).
So were Steve Krug, Jakob Nielsen and numerous others misleading the industry?
By all means, no. They were right all the time. Wait, what? Actually what they mean is 3/5/10 tests are enough to find a few issues which you can solve later. If a journey is very simple, 5 can indeed yield 85% of the issues. The main problem is that nowadays user journeys on live websites are rarely simple. If you compare a large eCommerce site from 10 or 15 years ago (when those numbers were born) to their current website you can easily see what I mean, ecommerce has changed for the better over the years, now more and more people visit website like https://www.raise.com/coupons/target every day just to make their purchases online.
In an ideal world you would solve a few issues, then test again after they got fixed. In reality, our enterprise clients there can be weeks or even months between finding an issue and solving it. The UX teams can be miles apart from the product team (sometimes even continents apart), and communication can be challenging. If you are a consultant working on a “redesign” project it’s even worse. There are numerous occasions when you want to find as many issues as possible and warn the organisation about them. Moreover sheer numbers can and will provide justification and validity, while certainly looking great. Imagine a business case where it is written “one out of five users tested could not use the date picker”. Now compare this with “For 19.46% of the users the date picker was a conversion blocker based on a remote user research; sample size 46”. Which is more likely to result in immediate action?
Small sample size can yield UX issues that are conversion killers for only a handful of users in the real world, and you might miss other issues that are a lot more common. This leads to wrong prioritisation and can even shake the belief in UX (or the abilities of the UX expert) when the changes for instance don’t bring measurable increase in conversions.
Futuresight
Please note, that this article comes with a “best before” date. And that date is 15th April 2015. Yes, it has already expired by the time you read this. This is because the web is in constant change. The journeys become more-and-more complex and the number of devices will explode, we are already experiencing the widespread availability of smart TVs and smart watches and in the very near future we will be able to see even more types of connected devices. But don’t worry, the research will not expire, and the basic idea that “3, 5 or 10 tests are not enough” will become even more obvious in the next couple of years months.
{kind=link}
When will companies start testing on larger sample sizes? Some do already, otherwise this research would not see daylight. And I hope even more will do so in the future, but then again: It is apparently an occupational disease, perhaps a fatal one, for the scientist to be too sanguine about eventual rule by reason.
(From They’d Rather Be Right by Mark Clifton & Frank Riley)
Leave a Reply